
新闻动态
2025-10-26 21:48 点击次数:150
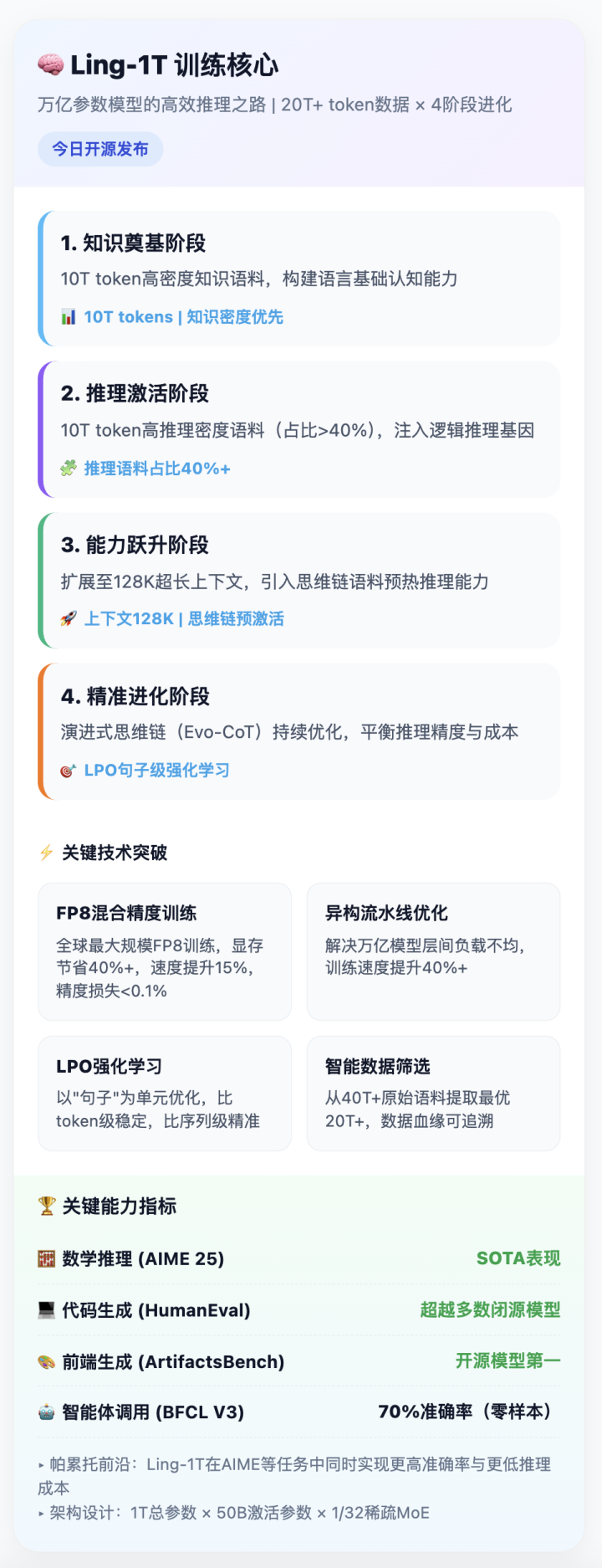
在人工智能领域,大模型的竞赛从未停歇,而如今蚂蚁集团带着其最新的成果——Ling-1T(百灵)加入了这场角逐。这款拥有1T参数、采用MoE架构的非思考语言模型,不仅在技术上有着诸多创新,更在实际应用中展现出了惊人的潜力。

蚂蚁的Ling-1T终于发了,大半夜的
中文叫百灵,1T参数,Instruct版本、非推理、MoE架构
HuggingFace:https://huggingface.co/inclusionAI/Ling-1T
GitHub:https://github.com/InclusionAI/Ling
在线体验:ling.tbox.cn(有API)
对于海外用户/开发者,还有个神奇的网站
ZenMux:https://zenmux.ai/inclusionai/ling-1t
国庆期间,提前玩了玩,素质ok
说这模型之前,容我先说蚂蚁:
这个蚂蚁,就是「蚂蚁森林」、「支付宝」的那个蚂蚁
蚂蚁的AI组织,叫InclusionAI
蚂蚁的模型,统称为百灵大模型,不是阿里的Qwen
Ling:语言模型,L取自Linguistics
Ring:思考模型,R取自Reasoning
Ming:多模态模型,M取自Multi-modality
理清这些很重要,别搞混了
小声逼逼:蚂蚁下个模型可以叫King,King和Qwen组CP
Ling-1T发布
这款模型,官方定位是「旗舰级非思考模型」,基本信息如下:
1TMoE,51B激活
128K上下文
20T+token语料预训练
注意,这里有个关键词:非思考模型
最开始的时候,大家的模型都是「非推理」的
比如原始的ChatGPT:你提问,模型答,没有思考
但从去年这时候开始,各家都在卷思考模型(你也可以叫它「推理模型」,就是ReasoningModel),最早是OpenAI的o1,然后是大火的DeepSeek-R1…
思考模型是这样:
给模型更多时间、中间token,让他用更长的推理链来提升准确率
你问它一道数学题,它会输出几千甚至上万tokens的内部思考,然后给你答案
Ling-1T的目标不一样:
在有限的输出token下,直接给出高质量的推理结果
看一组来自官方的对比,在AIME25,也就是美国25年的高中数学竞赛中:
Ling-1T:准确率70.42%,平均推理长度约4300tokens
Gemini-2.5-Pro(开thinking模式):准确率70.10%,平均推理长度约7000tokens
准确率差不多,但Ling-1T用的token少了40%
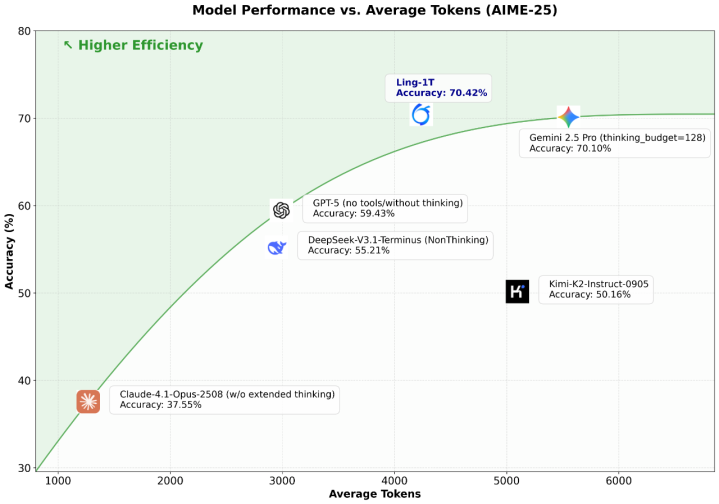
对于其他评测,数据如下(图片来自官方),大致就是:开源第一梯队
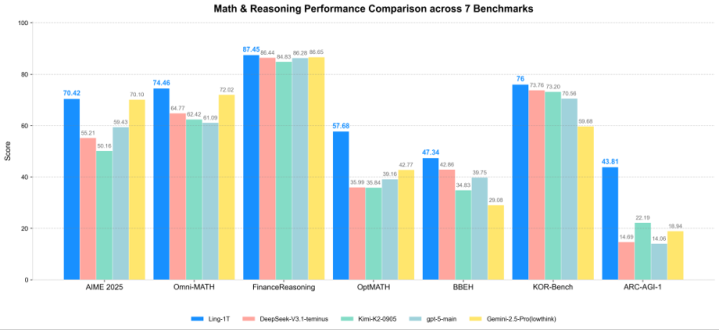
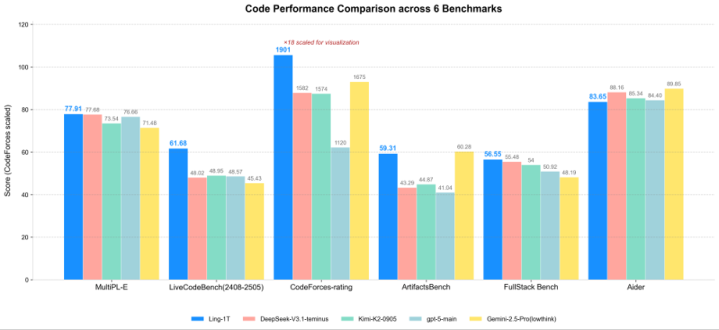
不过…等等,我看了一眼对比图里的其他模型数据,有点不对劲
比如GPT-5的AIME25分数,图里显示是60多分,但我印象里OpenAI发布的时候不是说90+吗?
然后我专门去查了下OpenAI的官方发布记录…
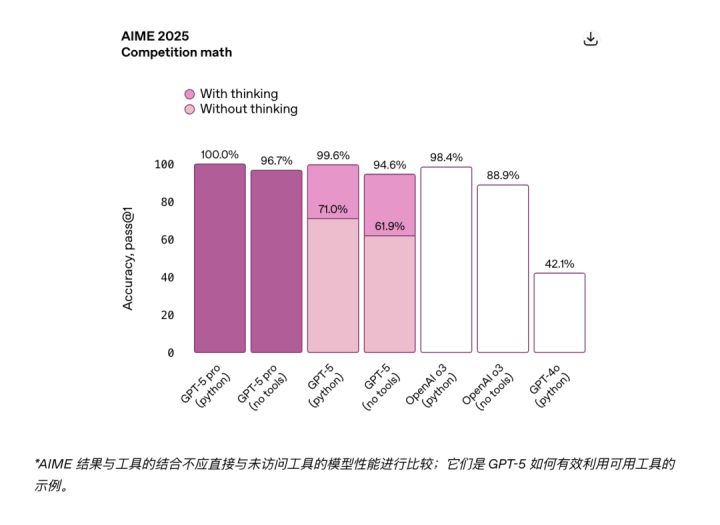
Hhhhh什么神奇的障眼法
GPT-5裸出结果(不开思考模式)的前提下
AIME2025的官方分数只有61.9%
月之暗面前段时间发布K2,也是1T参数,我拉来了里面的跑分
…OpenAI在图里的分数是37?
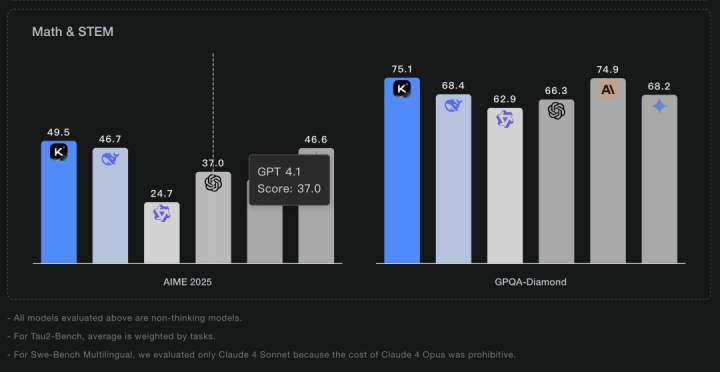
仔细一看,月之暗面选取的是GPT-4.1
其实吧…一点毛病没有
虽然现在的K2,版本号是0905,GPT-5已经出来
但K2-instruct发布的时候是7月11日,GPT-5还没出
在当时,OpenAI家当时最强模型,确实是GPT4.1
(顺道吐槽,GPT的发布顺序4.5->4.1->5)
各家对比的时候,选的参照模型版本都不一样
但不管怎么说,Ling-1T在非思考模型里的表现确实不错
技术实现
有关这个模型的训练,我来简单说一下吧
分架构、预训练和后训练三块
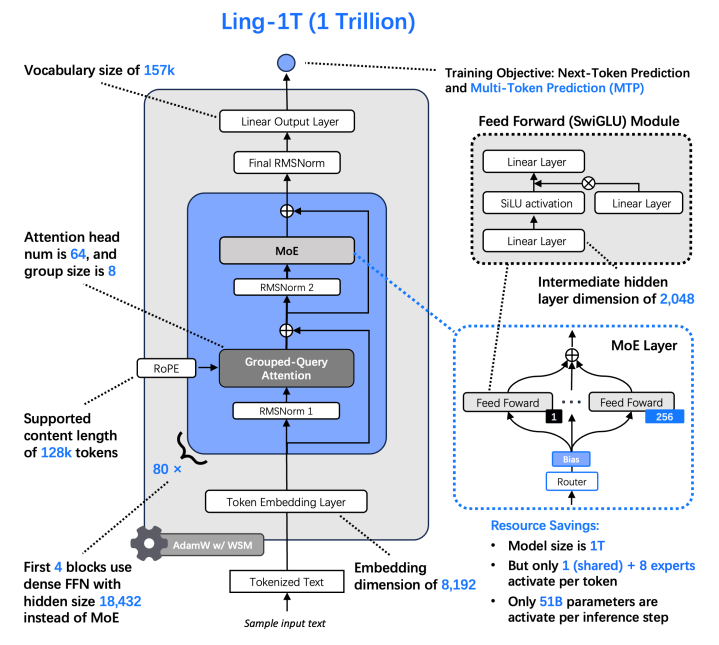
架构
Ling-1T用的是MoE架构:
1T总参数
256个专家
每次激活约51B参数
有个细节:前几层用的是密集结构(Dense),后面才切换到MoE。这种设计能在保证基础能力的同时,通过稀疏激活降低推理成本
至于为什么…说实话,我理解的不够深
于是问了这个模型的负责人,表示说:
firstkdense的设计,主要是为了降低浅层网络的负载不均衡;
浅层如果是moe的话,专家路由不均衡度会很高
改成前k个dense,后面再接moe,可以缓解这个问题
预训练
在预训练中,有三个阶段:
1.PretrainStage1(10Ttoken):高知识密度语料
2.PretrainStage2(10Ttoken):高推理密度语料,整体推理语料占比超过40%
3.Mid-training:扩展上下文到128K,加入思维链语料
这里的思路是:从一开始就训练推理能力
另外,Ling-1T全程用的是FP8精度训练,这是目前最大规模的FP8训练。相比BF16,FP8能省显存、提升训练速度,而且在1Ttoken的对比实验中,Loss偏差只有0.1%
后训练
蚂蚁提出了LPO方法(Linguistics-UnitPolicyOptimization),并表示:对于推理任务,句子是更符合语义逻辑的动作单元
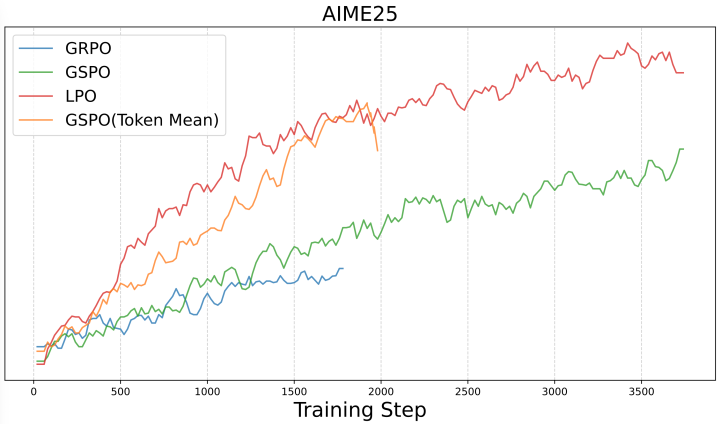
不同方法的训练效果,百灵团队提供
另外的,对于这些方法,这里做个小的辨析:
GRPO:按token优化
GSPO:按整个序列优化
LPO:按句子优化
实测
我得说,这个模型是超出我的预期的,比如我让他去做一个粒子波浪
当然,还可以再来个宇宙演化史
对于常规任务,比如信息卡片,也不在话下,内容就是他自己
有一说一,美术风格很讨喜,个人觉得甚至比ClaudeSonnet4.5好
对此,蚂蚁的朋友跟我说:
前端之前有专门优化过,也还在持续优化中
而对于svg的任务,也ok的,比如我让他
画一个svg动画:百灵鸟在尽情歌舞
给到了这个,还是可以的,甚至还有伪3D
(但微信里面传不了这么复杂的svg,这里放个gif)

我让Claude也画了个,大概是这样

百灵鸟在尽情歌舞
但也要控制预期:
指令理解这块,Ling比Claude还是有差距的
蚂蚁的AI
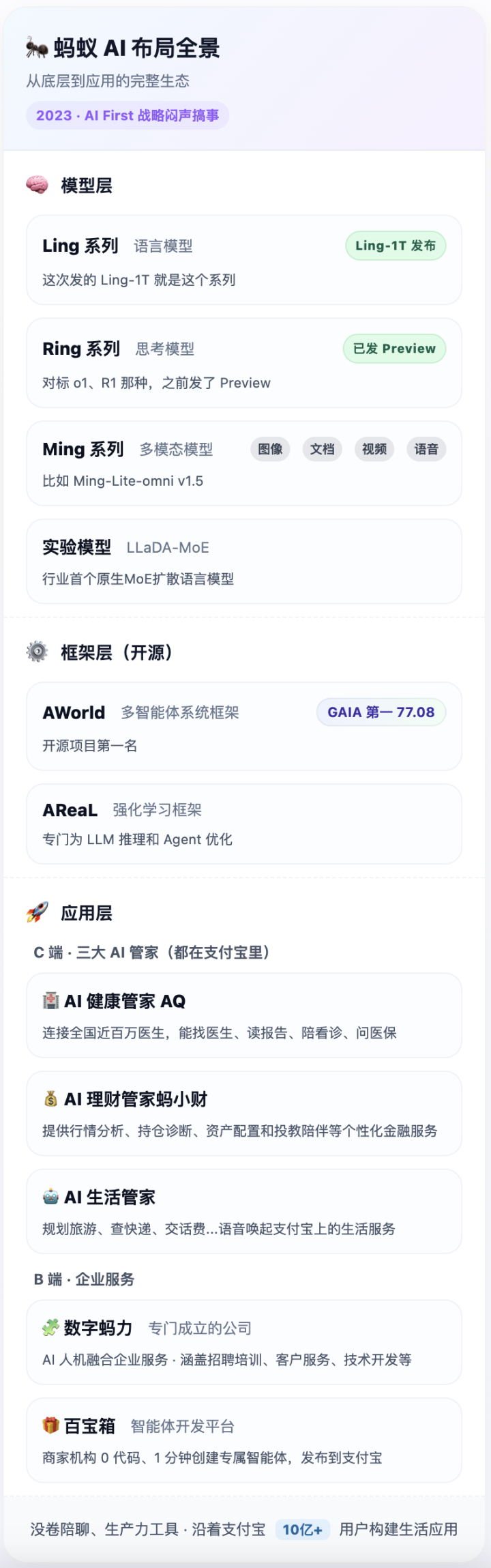
老实说,很多人可能不知道:蚂蚁还在训模型
从2023年开始,蚂蚁就确立了「AIFirst」战略,闷声搞事情
从底层,到应用,搞了一整套的完整生态
模型层,有三个系列:
Ling(语言模型):这次发的Ling-1T就是这个系列
Ring(思考模型):对标o1、R1那种,之后会发
Ming(多模态模型):就像Ming-lite-omniv1.5,能处理图像、文档、视频、语音以及…这里还有个实验版本LLaDa-MoE,是行业内首个MoE的扩散语言模型
框架层,开源了两个东西:
AWorld:多智能体系统框架,在GAIAbenchmark上拿了开源项目第一,77.08分
AReaL:专门为LLM推理和Agent优化的强化学习框架
应用层,分C端和B端
C端有三个AI管家,都在支付宝里:
AI健康管家AQ:连接全国近百万医生,能找医生、读报告、陪看诊、问医保
AI理财管家蚂小财:提供行情分析、持仓诊断、资产配置和投教陪伴等个性化金融服务
AI生活管家:能帮你规划旅游、查快递、交话费…语音唤起支付宝上的生活服务
B端也有两个:
数字蚂力:专门成立的公司,做AI人机融合的企业服务,涵盖招聘培训、客户服务、技术开发等
百宝箱:智能体开发平台,商家机构可以0代码、1分钟创建专属智能体,发布到支付宝
在这里,蚂蚁的打法有点不一样:没卷陪聊、生产力工具,沿着支付宝构建生活应用
这里做了张分享图,通过Ling画的,挺好看的
最后
在国庆假期的时候,和蚂蚁的技术人员也聊了聊,感觉很扎实
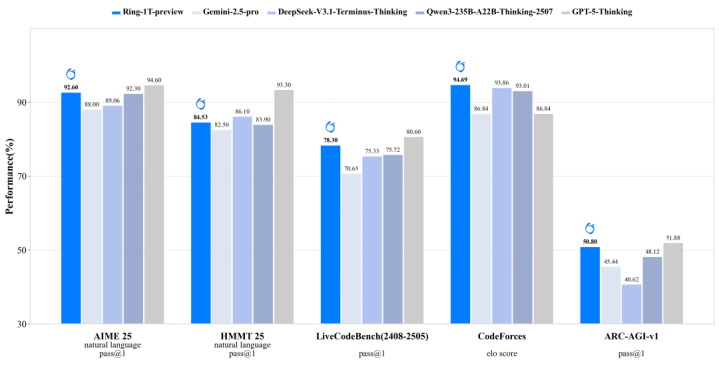
蚂蚁家的模型,这次是Instruct先发,思考模型Ring之后也会来
对于即将要发的Ring,跑分暂时是这样(还在提升ing)
而Ling,现在正式发布了,也有API能用,感兴趣的可以去跑跑看
HuggingFace:https://huggingface.co/inclusionAI/Ling-1T
GitHub:https://github.com/InclusionAI/Ling
在线体验:ling.tbox.cn(提供API)